PostgreSQL Streaming Replication With Docker
There are different methods for replicating data in PostgreSQL. In this article we will focus Streaming Replication method.
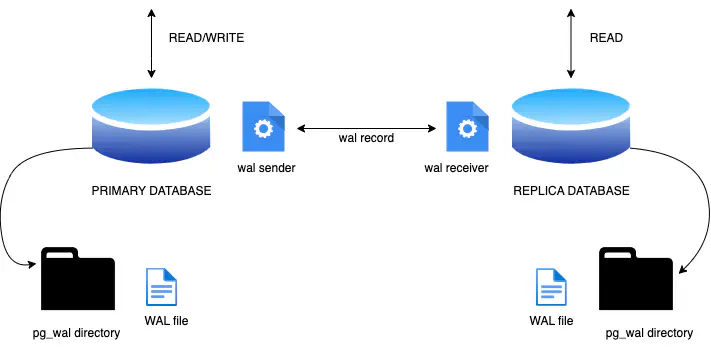
Overview
PostgreSQL streaming replication is a high-availability and data replication feature in the PostgreSQL relational database management system. It is designed to ensure the availability of your database by maintaining a real-time copy (or replica) of the primary database, which can be promoted to the primary role in case of a failure. This feature is particularly useful for load balancing, backup purposes, and maintaining system availability.
PostgreSQL streaming replication is a robust and well-established feature that is widely used to ensure data availability and reliability in PostgreSQL database systems. It can be an essential component of a high-availability architecture when combined with other techniques like load balancing and backup strategies.
How does streaming replication work
-
Primary Server: The primary server is the main PostgreSQL database server that handles read and write operations. It contains the master copy of the data.
-
Standby Servers (Replicas): Standby servers, also known as replicas, are additional PostgreSQL servers that replicate data from the primary server. There can be one or more standby servers.
-
WAL (Write-Ahead Logging): PostgreSQL uses the Write-Ahead Logging mechanism to record changes to the database. These write-ahead logs are used to replicate changes from the primary to the standby servers.
-
Streaming Replication: The primary server continuously streams its write-ahead logs to the standby servers. The standby servers apply these logs to their own databases, keeping them up to date with the primary.
-
Failover: In the event of a failure on the primary server, one of the standby servers can be promoted to the primary role. This ensures high availability and minimal downtime.
Types of Replication
Asynchronous Replication
-
Data Consistency: In asynchronous replication, data is considered committed on the primary database as soon as it’s written to its own transaction log, without waiting for confirmation from the replicas. Data consistency might lag behind slightly on the replicas.
-
Transaction: Asynchronous replication can result in lower latency for write operations on the primary database because it doesn’t have to wait for replication to complete. This makes it suitable for high-write-throughput scenarios.
-
Use Cases: Asynchronous replication is suitable when low-latency and high write throughput are more critical than strong data consistency. It’s often used in scenarios where minor data loss (the data lag on replicas) is acceptable.
Synchronous Replication
-
Data Consistency: Synchronous replication ensures strong data consistency. Data is not considered committed on the primary database until it is safely replicated to one or more secondary databases. This means that the data on the primary and secondary databases is always in sync.
-
Transaction: In synchronous replication, when a transaction is sent to the primary database and the synchronous replica(s), the primary database will wait for confirmation from the replica(s) before acknowledging the transaction as committed. This waiting for confirmation can introduce latency and might slow down write operations on the primary.
-
Use Cases: Synchronous replication is commonly used when data consistency is of utmost importance, and there’s a need for zero data loss (or very low data loss). It’s often employed in scenarios where financial or critical data integrity is essential.
Setting up streaming replication
We will have two postgres instances with one being the primary and the other as a standby(replica). We will be running our databases in docker containers.
Setting up Primary Database
Lets start the primary database in a docker container using below command:
docker run -d \
-p 5432:5432 \
-e POSTGRES_PASSWORD=password \
--name primary \
-v /Users/pashmantak/workspace/docker-volume-mounts/primary:/var/lib/postgresql/data \
postgres:14.5-alpine
Our primary database is running on port 5432 with user ‘postgres’ and password as ‘password’. We have also added a docker volume to map the postgres’s data directory to host’s directory.
Lets shell into to our primary db container and create a backup folder and take the backup of the database using pg_basebackup.
docker exec -it primary bash
mkdir /backup/
#take backup
pg_basebackup -D /backup/ -R -v -U postgres
#copy the back to primary's data folder which is mapped to an external volume
cp -r ./backup/ /var/lib/postgresql/data
#create archiver directory in primary
mkdir /var/lib/postgresql/data/archiver
Changes required in postgresql.conf
wal_level = replica
wal_log_hints = on
min_wal_size = 80MB
max_wal_size = 1GB
archive_mode = on
archive_command = 'test ! -f /var/lib/postgresql/data/archiver/%f && cp %p /var/lib/postgresql/data/archiver/%f'
max_wal_senders = 10
wal_keep_size = 512
Changes required in pg_hba.conf
# TYPE DATABASE USER ADDRESS METHOD
host replication replication_user < REPLICA_DB_IP > trust
In order to get the IP address of the replica db, we need to follow few steps before starting the replica container. Please complete the steps mentioned in Setting up Replica Database and resume the flow for primary database. Once replica is up, get its IP address and fill in the placeholder ‘REPLICA_DB_IP’ as shown above in ‘hba.conf’ file.
Next , we need to create the user ‘replication_user’ in the primary database with ‘replication’ role.
create user replication_user replication;
In order for changes to reflect , we need to restart our primary db container.
docker restart primary
After primary db container’s restart, you would be able to see started streaming WAL from primary at 0/3000000 on timeline 1 as shown in the below image.

Setting up Replica Database
Create a volume directory in the host for replica. This is needed to initiate our standby db with the primary’s backup state.
mkdir -p /Users/pashmantak/workspace/docker-volume-mounts/replica
#Copy the backup of primary to replica's volume.
cp -r /Users/pashmantak/workspace/docker-volume-mounts/primary/backup/ /Users/pashmantak/workspace/docker-volume-mounts/replica/
standby.signal which is present only in replica. Only if this file is present, then
a database can act as replica. This is not present in the primary db.
Changes required in postgresql.conf
listen_addresses = *
max_connections = 100
primary_conninfo = 'host=<PRIMARY_DB_IP> port=5432 user=replication_user'
Above properties need to be updated to the given value. ‘primary_conninfo’ is used to identify the primary db server. Get the primary db container’s ip address and update the ‘primary_conninfo’.
Changes required in postgresql.auto.conf
primary_conninfo = 'user=replication_user port=5432 host=<PRIMARY_DB_IP>'
Update the PRIMARY_DB_IP with the ip address of the primary db container and start the replica db container with below command on port 5433 (5432 is already in use by primary db container).
docker run -d \
-p 5433:5432 \
-e POSTGRES_PASSWORD=password \
--name replica \
-v /Users/pashmantak/workspace/docker-volume-mounts/replica:/var/lib/postgresql/data \
postgres:14.5-alpine
Lets test our setup
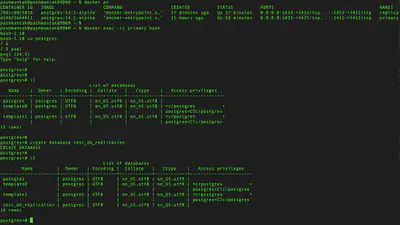
Lets shell into primary db container and create a database with name ’test_db’.
Verify that ’test_db’ database has been created in replica database.
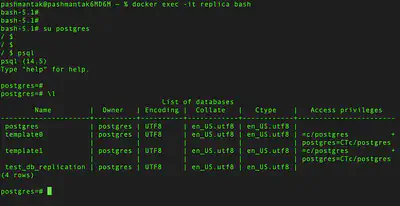
Streaming replication works !!